多模态生成框架新SOTA:文本+空间+图像随意组合,20W+数据开源,复旦腾讯优图出品
能处理任意条件组合的新生成框架来了!
复旦大学、腾讯优图实验室等机构的研究人员提出UniCombine,一种基于 DiT 的多条件可控生成框架,能够处理包括但不限于文本提示、空间映射和主体图像在内的任意控制条件的任意组合,并保持高度的一致性和出色的和谐性。
具体效果 be like:
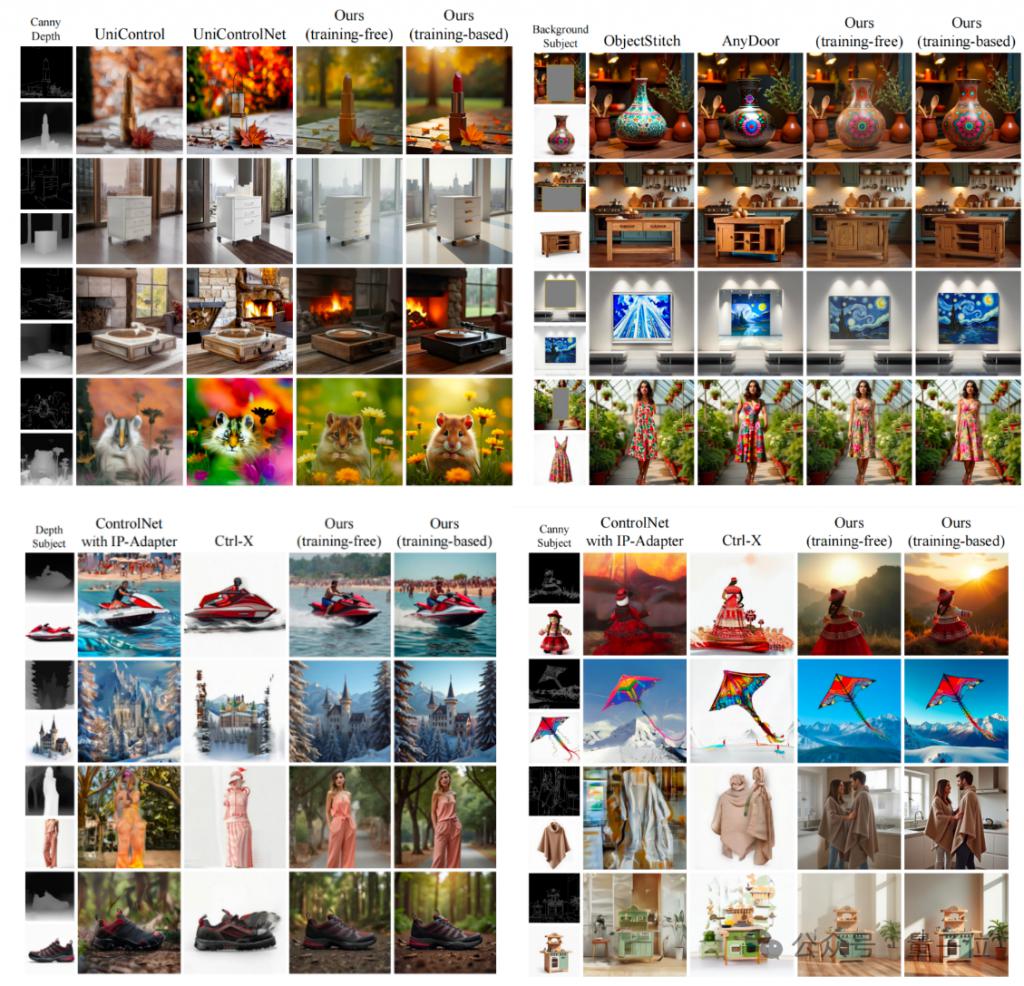
据了解,现有的多条件可控生成框架或是只能处理单一种类的多个条件,或是只适用于某种特定的多类别组合,从而普遍缺乏通用性的多类别 + 多条件的组合式生成能力。
而在 UniCombine 这项工作中,团队引入了一种新的 Conditional MMDiT 注意力机制,并结合可训练的 LoRA 模块,从而同时提供了 training-free 和 training-based 两种版本。
此外,团队构建并开源了首个针对多条件组合式生成任务设计的数据集 SubjectSpatial200K,其中涵盖了 subject-driven 和 spatially-aligned 两大类控制条件。
UniCombine 在 4 项不同的多条件可控生成任务上均达到SOTA,证明了新方法具有卓越的框架通用性和出色的条件一致性。
UniCombine 方法
UniCombine 框架图如下:
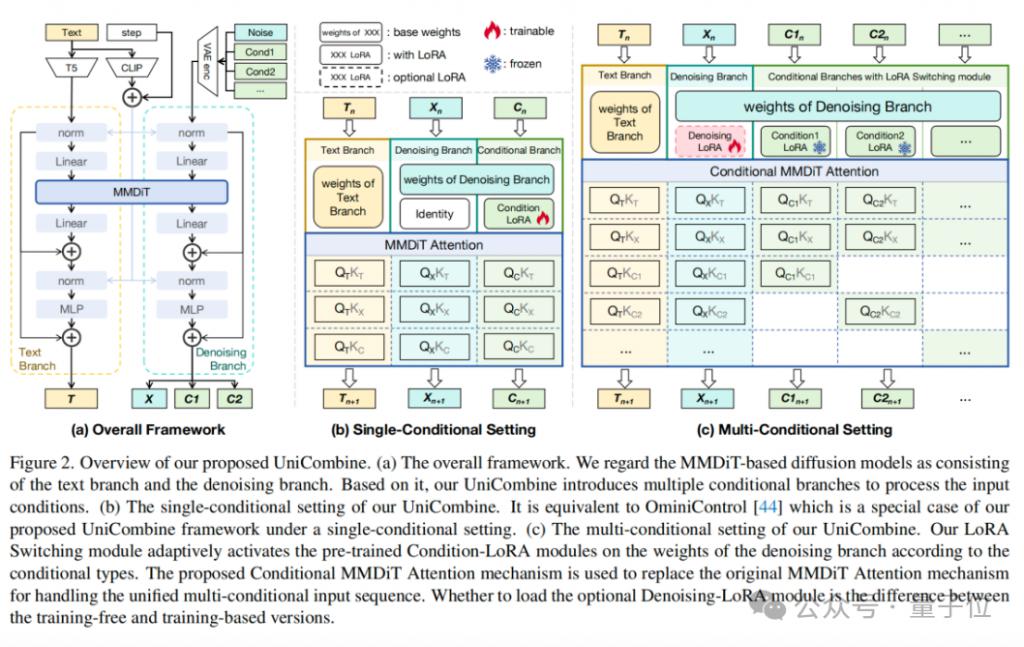
( a ) 整体框架。团队将基于 MMDiT 的扩散模型视为由文本分支和去噪分支组成。在此基础上,UniCombine 引入了多个条件分支来处理输入条件。
( b ) UniCombine 的单条件设置。该设置等价于 OminiControl,即在单条件设置下,OminiControl 是 UniCombine 框架的特例。
( c ) UniCombine 的多条件设置。团队提出的 LoRA Switching 模块可根据条件类型自适应激活去噪分支权重上的预训练 Condition-LoRA 模块。此外,团队引入了 Conditional MMDiT Attention 机制,以替换原始 MMDiT Attention 机制,从而处理统一的多条件输入序列。是否加载可选的 Denoising-LoRA 模块是无训练版本和基于训练版本的区别。
SubjectSpatial200K 数据集
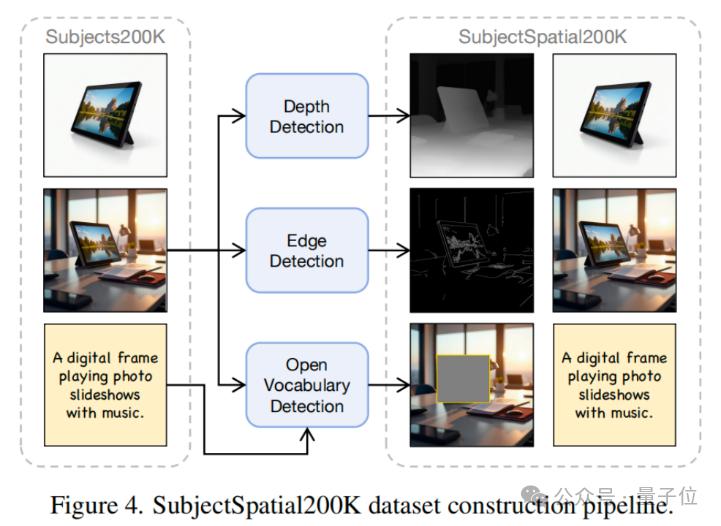
团队的 SubjectSpatial200K 数据集旨在填补当前多条件生成任务中缺少公开可用数据集的空白。现有数据集未能同时包含主体驱动和空间对齐的标注。
最近,Subjects200K 数据集提供了一个面向主体驱动生成的公开数据集。
在此基础上,团队构建了 SubjectSpatial200K 数据集,这是一个高质量的统一数据集,专为训练和测试多条件可控生成模型设计。该数据集包含全面的标注,包括丰富的 Subject Grounding Annotation 和 Spatial Map Annotation。数据集的构建流程见图。
实验结果
(1)对比实验
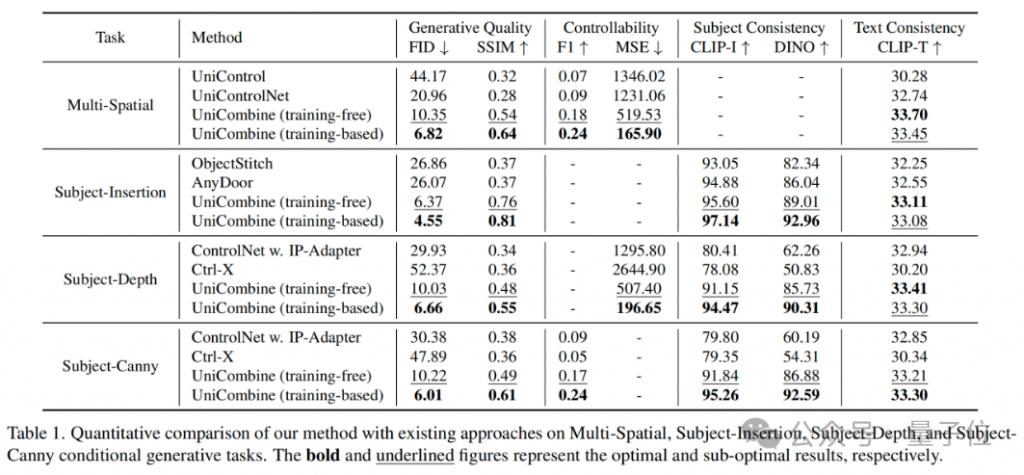
(2)消融实验:CMMDiT 与 MMDiT

(3)消融实验:Denoising LoRA 与 Text-LoRA

(4)消融实验:DSB+SSB 联合训练与 DSB 单独训练

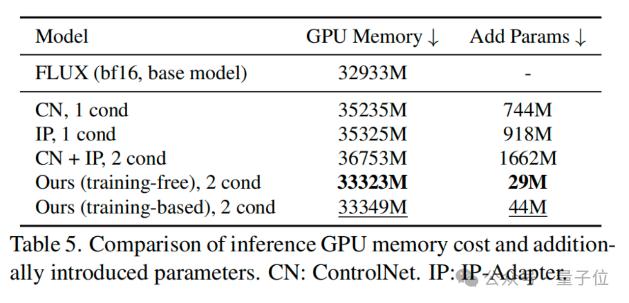
(5)算力开销分析
整体而言,研究人员提出了 UniCombine,这是一个基于 DiT 的多条件可控生成框架,能够处理任意条件组合,包括但不限于文本提示、空间映射和主体图像。
在主体插入、主体 - 空间以及多空间等条件生成任务上的大量实验表明,无论是无训练还是基于训练的版本,UniCombine 都达到了最先进的性能。
此外,团队提出了 SubjectSpatial200K 数据集,以弥补当前缺少用于训练和测试多条件生成模型的公开数据集的不足。团队相信,该研究将推动可控生成领域的发展。
论文链接:
https://arxiv.org/pdf/2503.09277
开源代码:
https://github.com/Xuan-World/UniCombine
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文 / 项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

点亮星标
科技前沿进展每日见