科大讯飞挺身而出

人工智能正走在波涛汹涌的爆发期。越是浪潮涌动,越容易凝聚剧烈的变化。生成式 AI 的快速进步,也给旷日持久的科技竞赛画出了一条崭新的跑道。
在产业升级与科技自主的语境下,中国人工智能也到了阶段性检验阶段。国产算力替代酝酿已久,国产大模型发展渐入佳境,一场摧枯拉朽的 AI 生态重塑正在进行。
这场重塑,突破了 " 卡脖子 " 难题,算力追赶和算法创新齐飞,技术进步和产业应用共同发生。
五军之战:中国不只有 Deepseek
Deepseek 横空出世,打破了 AI 的算法焦虑,也吸引了世界的目光。
一个季度过去了,中国 AI 厂商正在形成 " 五军之战 " 的竞争态势:DeepSeek、字节豆包、阿里通义、腾讯混元、讯飞星火。
最新的进展是:4 月 20 日,科大讯飞推出最新升级版的深度推理大模型——讯飞星火 X1,其独一无二的身位是 " 目前为止,唯一基于全国产算力训练的深度推理模型 "。
《南华早报》在报道中大写加粗的写上了 " 无需英伟达 "(No need for Nvidia) [ 1 ] 。
《南华早报》:无需英伟达,科大讯飞发布使用华为 AI 芯片训练的推理模型
这意味着,中国AI在算法创新之外,再次突破算力局限,实现了全栈自主可控。
" 国产算力 " 的突破并非偶然,也不能完全归因于地缘环境,其根本原因在于:人工智能的竞争,已从算法与模型的性能优劣,变成了算力 / 算法 / 应用的综合能力的考验。
如果将算力比作拳击手的一身腱子肉,没有精湛的战术匹配,瘦子一记扫堂腿就能让其败下阵来。算法就是战术,能让拳击手的每一寸肌肉(算力)都发挥出应有的攻击力。
目前,中国算力面临的难点有:英伟达禁售令、国产芯片的技术差距以及算力基建的供需平衡。
中国 AI 企业的答卷各不相同:有的沿用 " 大力出奇迹 " 的路线,用实力和资本铺路,比如字节豆包、阿里通义、腾讯混元等;有的以小博大,通过算法创新,从国民级 C 端应用切入,效果惊艳,如 DeepSeek;还有的则破釜沉舟,用全国产化算力、算法和数据,实现全栈自主可控,如讯飞星火。
最引人注目的是后两条路线。
Deepseek 用算法创新,颠覆了行业惯性思维。
知名半导体研究机构 SemiAnalysis 指出,随着算法的进步,大模型实现相同功能所需的计算量每年会减少四倍 [ 2 ] 。
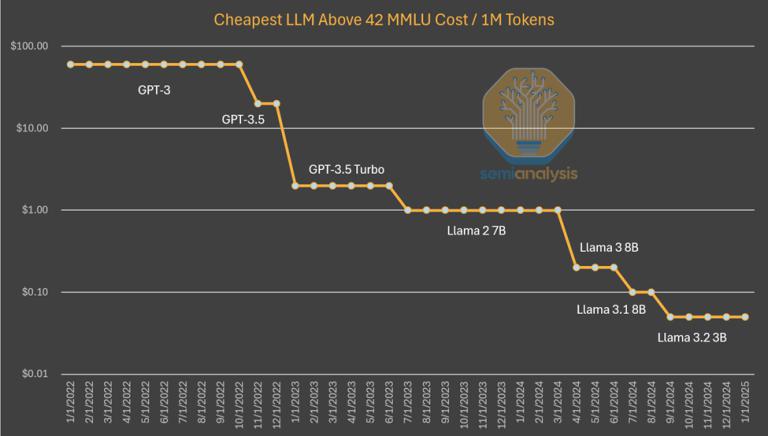
科大讯飞的路线更为陡峭:用全国产化算力的突破和算法的创新,研发出了全栈自主可控的全国产化大模型。
早在 2023 年 10 月 24 日,科大讯飞就宣布首个支撑万亿参数大模型训练的万卡国产算力平台 " 飞星一号 " 正式启用。
科大讯飞携手华为,通过算子融合、混合并行策略等创新技术实现了昇腾 910B 算力的适配和优化并大幅提升训练效率,训练效率相比英伟达 A100 从 55% 提升到 85%。讯飞星火大模型就是在 " 飞星一号 " 平台上训练出来的。
2025 年 1 月 15 日,科大讯飞又发布了国内首个基于全国产算力训练的具备深度思考和推理能力的大模型——讯飞星火 X1。
10 天前,讯飞研究院宣布,联合团队通过多种优化手段提升 " 飞星一号 " 平台上 MoE 模型集群推理的性能上限,并实现大规模专家并行集群推理性能翻番。之后,讯飞星火 X1 迎来全新升级,在数学、代码、逻辑推理、文本生成、语言理解、知识问答等通用任务上效果显著提升,在模型参数比业界同类模型小一个数量级的情况下,整体效果对标OpenAI o1 和 DeepSeek R1,再次证明了基于国产算力训练的全栈自主可控大模型具备登顶业界最高水平的实力和持续创新的潜力。
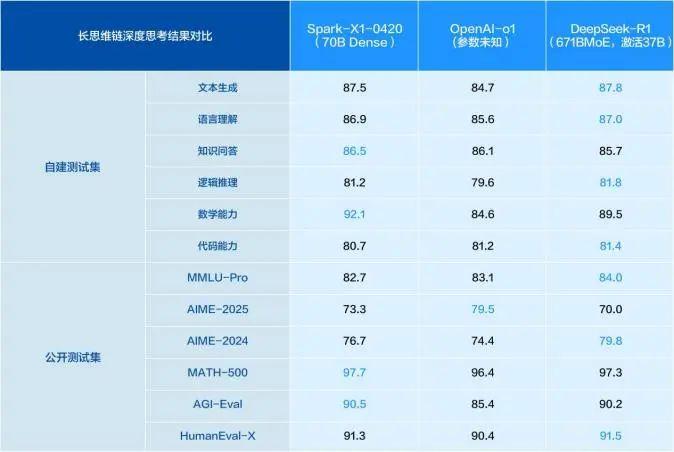
讯飞星火 X1 最值得关注的地方,并非只是模型本身的能力上与国内外先进水平平齐,更是在 " 自主可控 " 的语境下,给地缘阴云笼罩中的产业界提供了一条破局之路。对中国 AI 行业来说,这是一次里程碑式的技术跃升,也是对当下自主可控紧迫需求的有力回应。
科大讯飞、华为、合肥市大数据资产运营有限公司三方联合打造的中国国产超大规模智算平台 " 飞星二号 " 将于今年交付首批算力。
应用为王:找到客户需求的最大公约数
" 全栈自主可控 ",不仅在技术研发上,更在产业应用上。
产业应用的难点在于 " 既要且要还要 ":不仅需要模型有能力应对客户和用户不同层面的需求,还需要考虑在终端运行时的功耗限制、搭载模型的成本、响应时间等问题。
当人们开始冷静审视大模型究竟能为自己的工作和生活带来多大效用,就需要模型厂商跳出 " 参数为王、算力制霸 " 的视角,通过算法和解决方案的创新,为上述需求找到最大公约数。
当前业内公认的两个事实是:一是好的解决方案,能带来部署成本的大幅下降;二是提高推理能力,为客户提供性价比高的模型规模。这背后是:工程能力与技术能力两手抓,两手都要硬。
科大讯飞通过 " 通专结合、端云联动与软硬一体 "(通用大模型与专业大模型结合、端侧大模型与云端大模型联动、软硬件一体化)来实现部署成本与用户体验的平衡,打通商业化的通道,并提出 " 建算力、理数据、训模型,到落场景、保安全、精运营 " 的全链路方法,从场景出发,给客户提供人工智能的解决方案。
在工具层面上,科大讯飞进一步升级了模型定制优化工具链,支持监督微调、强化学习两种模型定制优化方案,进一步简化了定制步骤和成本。
在推理性能上,最新升级的讯飞星火 X1 通过三大核心技术创新——大规模多阶段强化学习训练方法、基于快慢思考的统一训练方法、工程技术系统创新保障基于国产算力的高效长稳训练。其满血版以 70B 大小的参数量,推出 " 快思考、慢思考统一模型 ",由一个模型同时支持两种思考模式,模型部署仅需 4 张卡(华为 910B),整体效果就能对标 OpenAI o1 和 DeepSeek-R1。
除了常见的通用任务,讯飞星火 X1 由于融入了更多行业场景的复杂类型数据,其泛化性得到很大提升的同时,在多个行业任务上也展现出业界领先的能力。在重点行业如教育、医疗、司法等进一步扩大了领先优势。
目前,星火 X1 API 已同步上线讯飞开放平台,面向广大开发者和企业开放服务。
当人工智能的竞争焦点转向技术能力、市场洞察、解决方案为代表的综合能力的比拼时," 姜还是老的辣 " 这句俗语的含金量还在提高。
AI 应用 2.0 时代:科大讯飞很难被复制
在正在进行的 2025 上海车展上,科大讯飞集中展示了讯飞星火大模型在智能座舱、智慧声场、车企数智化等领域的最新成果,被消费者和行业客户广泛关注。据介绍,讯飞星火大模型落地奇瑞、广汽、长城、长安、大众、江淮、一汽、日产等车企 16 款量产车型," 大模型上车 " 正进入密集量产阶段。
业界认为,2024 年是大模型应用的元年,而今年可能就是爆发之年。
中国的AI产业生态进展迅速。如果说大模型应用 1.0 阶段的特点是:Demo 产品、通用功能、日常助手,那么其正在进入 2.0 的更深度阶段:规模化、个性化、场景化。
比如,上海车展上亮相的星火汽车智能体平台,能够深度融合智能交互能力,帮助客户快速打造智能体应用,构建差异化竞争力。目前,科大讯飞已基于智能体平台构建了赛事、影音、新闻、美食、出行等示范智能体。同时讯飞还提供丰富的开源大模型能力和知识库能力,以及汽车领域专属生态和工具,可支持车企组合定制,打造个性化的座舱场景。

再以市场风向标央国企领域为例,根据IDC报告,科大讯飞凭借算力和模型一体化优势,位居 2024 年央国企大模型解决方案市场份额第一,领先百度、阿里。今年,央国企的大模型部署再 " 向前一步 "。
中国石油去年与中国移动、华为、科大讯飞共建的昆仑大模型,发布涵盖 43 个专业应用和通用应用创新场景。今年,昆仑大模型完成了新一轮模型能力、应用场景迭代和新增,并对外发布 " 行业大家 ",面向能源化工领域,打造综合性知识服务与信息检索平台。
中海油在去年十月携手科大讯飞推出 " 海能 " 人工智能模型,科大讯飞根据行业特性,针对性推出多个通用场景模型,针对招标采办、员工健康、辅助办公等需求。今年,专业场景模型的建设已在研发,包括海上油田稳产增产、安全钻井、海工制造等领域。
在智慧城市领域,科大讯飞将城市智算中心的建设与大模型应用结合,通过 " 算力 + 数据 + 算法 + 场景 + 生态 " 五维体系,助力城市打造 AI 产业底座,提高城市算力中心的利用率,推动传统产业智能化升级。在湖北利川武陵山(利川)人工智能计算中心项目中,科大讯飞帮助打造了全国首个县域文旅大模型,构建起覆盖游客、商户、政府的三端服务体系。
在科研领域,科大讯飞联合中科院大连化学物理研究所研发 " 化工大模型 ",已部署化工知识问答能力,正研发结合知识溯源能力、深度推理能力、多模态能力为一体的新版本……
目前,科大讯飞 " 通用 + 专业 " 大模型模式已与 20 多家头部企业合作,覆盖 300 多个场景。产业化深水区是综合能力的比拼,对模型厂商的两大能力提出了要求:一是模型泛化能力,二是应用行业的专业能力。
模型泛化能力,指机器学习模型在未见过的数据上表现良好的能力,即从训练数据中学到的规律能够有效迁移到新数据中的能力。简而言之,就是能否用标准化的模型,更低的部署门槛,满足不同客户 / 用户的个性化需求。
如果说模型泛化能力,考验的是厂商的技术硬实力;那么应用行业的专业能力,则是考察厂商的商业化思维、行业的积累,甚至对技术链接人类福祉的深刻理解。
科大讯飞并非大模型时代的新玩家,而是中国人工智能产业的第一批探索者。26 年来,从智能语音技术,到认知智能(包括机器翻译、机器阅读理解、OCR 等技术),再到如今的大模型技术," 人工智能 +" 的每一步都走得扎实。
技术体系也许可以追赶,但深耕行业的专业、丰富的软硬件产品矩阵、完善的服务支持能力、长期积累的产业化思维与经验,却很难被继承和复制。这既是新老巨头重新拉开距离的分界点,也是科大讯飞的优势所在。
近日,科大讯飞披露 2024 年年报。年报显示,公司全年实现营业收入 233.43 亿元,同比增长 18.79%,时隔两年重回双位数增长,同期归母净利润为 5.6 亿元。此外,科大讯飞现金流创下历史新高,截至 2024 年末,公司全年经营性现金流净流入 24.95 亿元,同比增长超 6 倍。
尾声
一个显而易见的事实是,以 DeepSeek、科大讯飞等为代表的国产大模型,正在快速弥合与国际顶尖大模型之间的差距,并推动本土生成式 AI生态走向可持续的循环以及更加强劲的发展轨道。
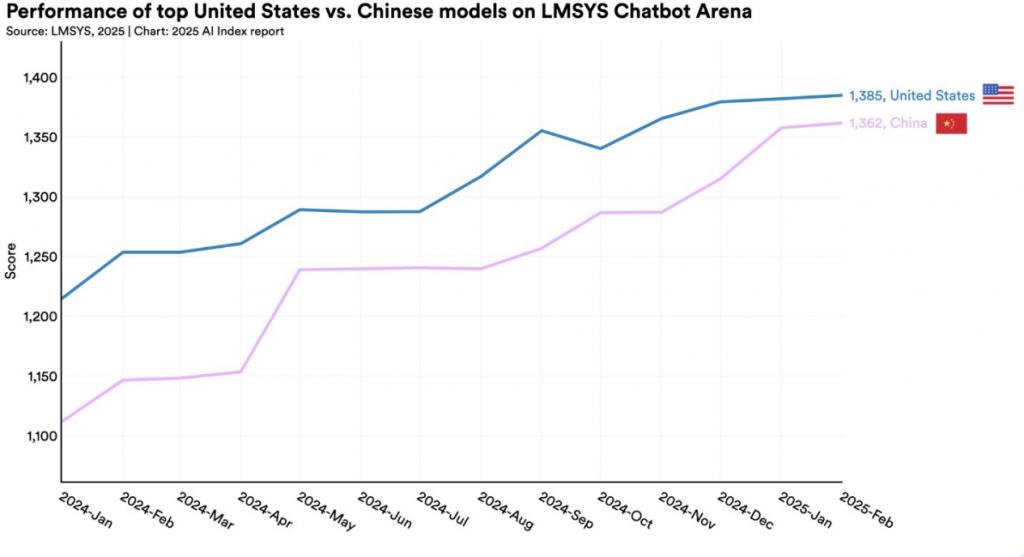
斯坦福大学以人为本人工智能研究所 4 月初发布《2025 年人工智能指数报告》指出,根据 MMLU 和 HumanEval 等主要基准测试结果,中美大模型性能差距已从 2023 年的两位数缩小到 2024 年的接近持平 [ 5 ] 。
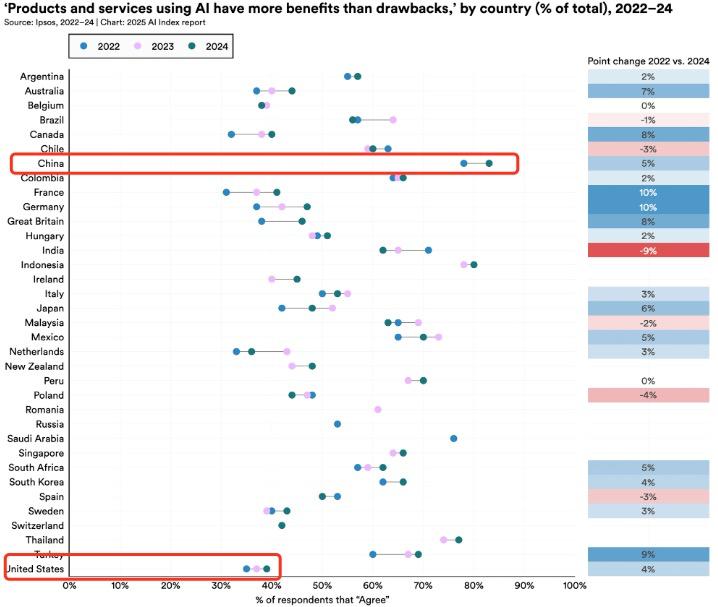
同时,对于 " 产品和服务采用 AI 技术的好处大于坏处 " 的问题,中国的认同比率达到 83%,在调查国家中位列第一,而大模型实力公认最强的美国,这个数字仅为 39% [ 4 ] 。
相较于在过去几次科技浪潮中的漫长追赶,在生成式 AI 的赛道上,从跟跑到持平,中国只用了两年。
更值得一提的是,中国人工智能正在政府、科研机构、行业、企业、开发者等多方的共同努力下,走向应用与产业生态的繁荣。" 人工智能国家队 " 科大讯飞,在算力自主、算法创新的基础上,不断拉长工程能力和行业专业能力的长板,在当下风险与机会并存的大势之下,挺身而出,率先走出了自己的破局之道。
参考资料
[ 1 ] No need for Nvidia: iFlytek touts reasoning model trained entirely with Huawei ’ s AI chips,SCMP
[ 2 ] DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts,SemiAnalysis
[ 3 ] On DeepSeek and Export Controls,Dario Amodei
[ 4 ] The 2025 AI Index Report,Stanford HAI
作者:何律衡

